遠藤研究室の今年度の研究室紹介を、下記の日時で開催します。
- 第一回:2018/2/5(月) 13:20~14:50
- 第二回:2018/2/6(火) 10:45~12:15
場所:西7号館203号室集合 → 会場へ (直接下記会場に来てokです)
- 第一回:西7号館205号室
- 第二回:西7号館302会議室
出席希望者は、前もって endo[at]is.titech.ac.jp にメールもしくは、Twitter ToshioEndoに連絡もらえると助かりますが、予告なしでの参加もお気軽にどうぞ。
どちらにも都合がつかないが話を聞いてみたい、という場合も上記に連絡ください。
並列/分散/協調処理に関する『秋田』サマー・ワークショップ (SWoPP2017)は7/26~28に秋田で行われ、当研究室からは4件のメモリCRESTプロジェクトに関する発表を行いました。
- 松宮 遼,遠藤 敏夫. vGASNet: メモリ階層深化に向けたスケーラブルな低レイヤ通信ライブラリ

- 田邊 昇,遠藤 敏夫. Intel Xeon Phiにおける主記憶遅延増加の影響評価

- 幸 朋矢,佐藤 幸紀,遠藤 敏夫. Polyhedralコンパイラを用いたタイリングパラメータ自動調整ツールのメニーコア環境での評価

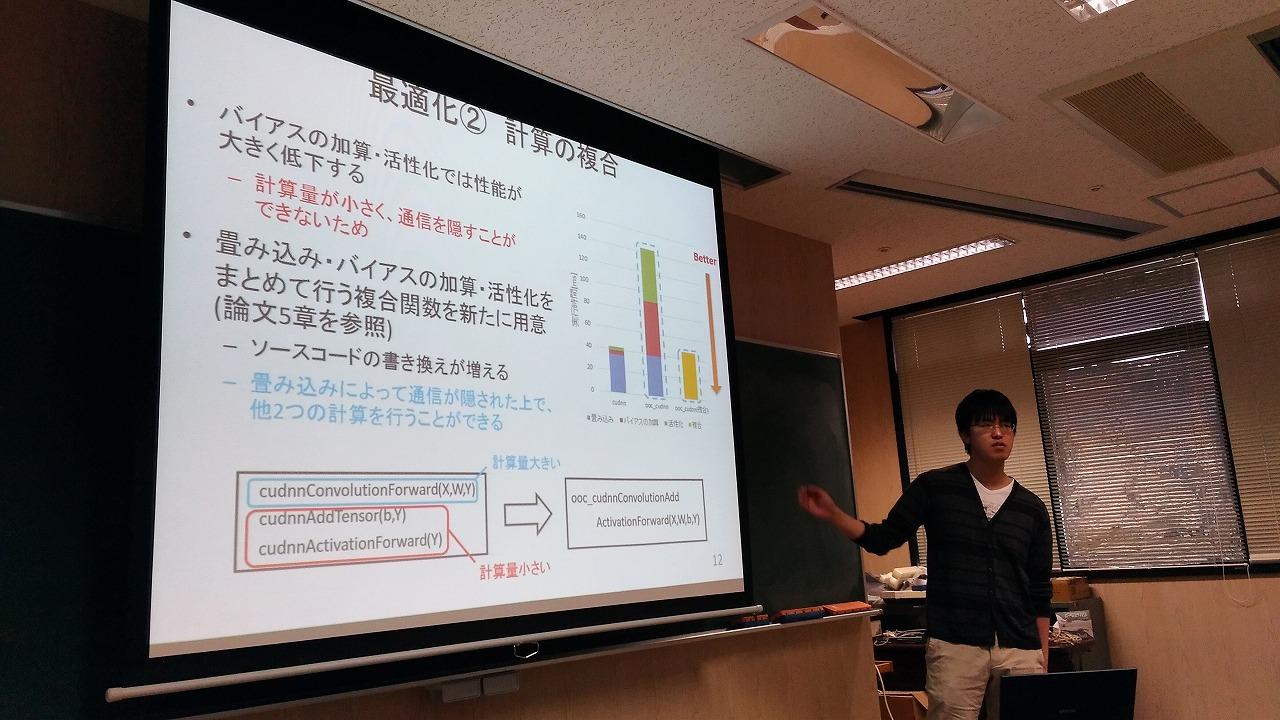
- 伊藤 祐貴,松宮 遼,遠藤 敏夫. ooc_cuDNN: GPU計算機のメモリ階層を利用した大規模深層学習ライブラリの開発

2017年2月9~10日に情報科学科の卒業論文発表会があり、当研究室からは伊藤君が発表しました。
- 伊藤祐貴:メモリ階層を利用した大規模深層学習手法と性能モデリング
Convolution Neural Networkの演算はGPGPUにより高速に行うことができる一方、計算のサイズについてはGPUのメモリ容量(数~十数GBで、ホストメモリより小さい)により限定されます。その容量を超えるようなサイズの計算が可能で、cuDNNライブラリと互換性を持つooc_cuDNNライブラリを開発中で、性能モデルによる最適化も行っています。
4月に虎ノ門で行われるxSIG会議での発表も決まっています。
2016年11月にSalt Lake Cityで行われたSupercomputing '16会議の併設ワークショップESPM2(International Workshop on Extreme Scale Programming Models and Middleware)で,博士一年の松宮遼君が発表を行いました.
Ryo Matsumiya, Toshio Endo: PGAS Communication Runtime for Extreme Large Data Computation
PGAS(partitioned global address space)システムであるGlobal Arraysを用いたアプリケーションに対して,実メモリ容量を超えるような実行(out-of-core実行)を透過的に実現するライブラリの設計・評価について発表しました.


なお,8月のSWoPP'16@松本でも発表を行っています.

遠藤研究室一期生の三人が2月に修士論文発表を行い、無事修士課程修了しました。おつかれさまでした。
- 佐々木 尚人:時間発展アプリケーションにおけるチェックポイントデータの非可逆圧縮手法の提案と評価

- 辻田 裕紀:マルチGPU・マルチノード環境のメモリ階層に適応した数理最適化ソルバー向けスケジューリング手法

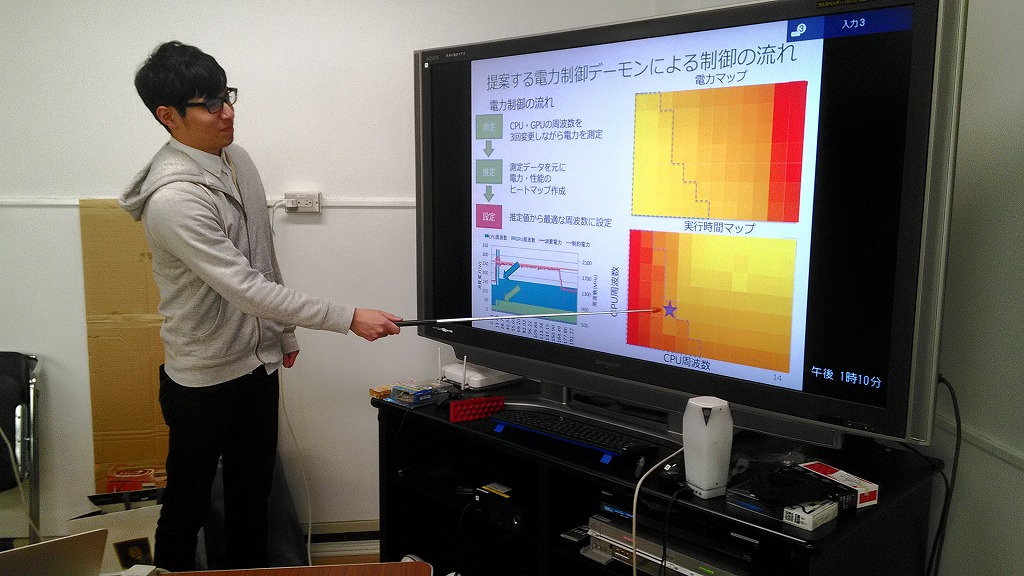
- 都筑 一希:CPU・GPU混載ノードにおける性能・消費電力モデルを用いたオンライン電力制御手法
※発表会での写真がピンボケしてしまったため、後日の説明の様子
2015年11月に行われたSupercomputing '15会議の併設ワークショップESPM2 (International Workshop on Extreme Scale Programming Models and Middleware)にて、修士二年の辻田裕紀君が発表を行いました。
Yuki Tsujita, Toshio Endo, Katsuki Fujisawa: The Scalable Petascale Data-Driven Approach for the Cholesky Factorization with Multiple GPUs (slides)
九州大学藤澤克樹先生が中心に開発している数理問題最適化ソルバーSDPARAについて、数千基以上のGPUを使った際の性能をさらに向上させる改良を行いました。
コレスキー分解の計算部分を、データドリブン方式で行う・GPUとCPU間のデータ移動量を抑えた分散データ処理基盤を実装する・非同期ブロードキャスト相当の通信をスケーラブルに行うなどの工夫を行いました。これにより、TSUBAME2.5ほぼ全体の1360ノード・4080GPU上で1.775PFlopsを達成しました(世界記録更新!)

大変遅い記事ですが…
修士学生3人が、5月の国際会議で研究発表を行いました。
SmartGreens2015@Lisbon, Portugul
・Kazuki Tsuzuku, Toshio Endo. Power Capping of CPU-GPU Heterogeneous Systems Using Power and Performance Models.

IEEE IPDPS 2015@Hyderabad, India
・Naoto Sasaki, Kento Sato, Toshio Endo, Satoshi Matsuoka. Exploration of Lossy Compression for Application-level Checkpoint/Restart

・JSSPP workshop, held with IEEE IPDPS 2015@Hyderabad, India
Yuki Tsujita, Toshio Endo. Data Driven Scheduling Approach for the Multi-node Multi-GPU Cholesky Decomposition

5月18~19日に、東京大学(本郷)で開催された情報処理学会HPCS2015にて、遠藤研から多数の発表を行いました。
- 論文発表
- 高嵜 祐樹,遠藤 敏夫,松岡 聡. GPUクラスタにおける大規模都市気流シミュレーションの最適化と性能モデル.(発表者:遠藤)
- ポスター発表
- 辻田裕紀, 遠藤敏夫. マルチノード・マルチGPU上のコレスキー分解に対するデータドリブン型アルゴリズム手法.
- 佐藤幸紀,佐藤真平.メモリ階層性能シミュレータを用いたCPU単体性能チューニング.
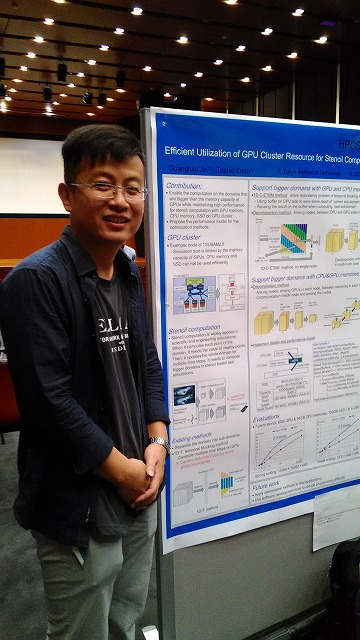
- Guanghao Jin,Toshio Endo. Efficient Utilization of GPU Cluster Resource for Stencil Computation.
- 遠藤敏夫. 異種プロセッサマシンのメモリ階層を活用するHHRT ライブラリの実装.



3月17~19日にアメリカ・サンノゼで開催されたGPU Technology Conference (GTC 2015)において、修士一年都筑君がポスター発表を行いました。
- Kazuki Tsuzuku, Toshio Endo: Power Capping of CPU-GPU Heterogeneous Systems using Power and Performance Models
コンピュータシステムの省電力・省エネの重要性については言うまでもありませんが、GPUなどのアクセラレータを搭載した高性能計算用コンピュータにおいてはPCなどと違った方法をとる必要があります。計算負荷がほぼずっと高い状況でも省電力を行う必要があること、電力上限の遵守だけでなく計算に係る消費エネルギーを抑制する必要があること、アプリケーションの性質によって最適なGPU/CPUクロックが異なること・・・を考慮する必要があります。そのためにリアルタイム電力を用いる動的制御と、電力・性能モデルを用いる静的制御を組み合わせるハイブリッド手法について提案しました。

7月16日に東京ミッドタウンで開催されたGTC Japan 2014に研究室メンバーが参加しました。
ポスターセッションでは研究員の金さんがポスター発表を行い、NVIDIA Awardを受賞しました。
Guanghao Jin, Toshio Endo: "Data Management and Loop Controlling to Surpass Memory Capacity of GPU in OpenACC Framework"