- 相川 洋貴:時間ブロッキングを用いたステンシル計算のドメイン特化言語による高性能実装と評価
流体シミュレーションなどで用いられるステンシル計算の高速化のためには時間ブロッキングというメモリアクセス局所性向上手法が有用であることが知られていますが、手作業ではプログラミングが大変煩雑という問題がありました。多次元配列計算のためのドメイン特化型言語Halideでそれを記述し、容易な記述で高い性能がえられることをマルチコア計算機上で示しました。

東京科学大学遠藤研究室では、 スーパーコンピュータをはじめとする高性能計算システムのための ソフトウェアやアルゴリズムなどの研究を、 TSUBAME4.0スパコンなどを用い行っています(2024年9月までは東京工業大学遠藤研究室)。 近年はGPUを用いたディープラーニングの大規模化・高速化の研究も行っています。 スパコンアーキテクチャは年々、並列度の増大や、メモリ階層の複雑化など、変遷し続けています。 それらを利用しやすくするソフトウェアやアルゴリズムの進展が求められており、 本研究室では関連の深い研究室や異分野の研究室とも共同して研究に取り組んでいます。
学部生の配属については、情報理工学院 数理・計算科学系から志望することができます。
他大学からは大学院入試をご検討ください。スケジュールに関しては大学の入試情報ページ(修士課程入試、博士後期課程入試)などを参照ください。
]]>研究室はすずかけ台キャンパスですが、今回は大岡山で行います。
Zoomにて開催します。
出席希望者は、前もって endo[at]is.titech.ac.jp にメールもしくは、Twitter ToshioEndoに連絡をお願いします(Zoom URLなどお知らせします)。
時間の都合がつかないが話を聞いてみたい、という場合も上記に連絡ください。日時を調整させてもらいたいと思います。
]]>Zoomにて開催します。
出席希望者は、前もって endo[at]is.titech.ac.jp にメールもしくは、Twitter ToshioEndoに連絡をお願いします(Zoom URLなどお知らせします)。
時間の都合がつかないが話を聞いてみたい、という場合も上記に連絡ください。
]]>流体シミュレーションなどで用いられるステンシル計算の高速化のためには時間ブロッキングというメモリアクセス局所性向上手法が有用であることが知られていますが、手作業ではプログラミングが大変煩雑という問題がありました。多次元配列計算のためのドメイン特化型言語Halideでそれを記述し、容易な記述で高い性能がえられることをマルチコア計算機上で示しました。
上記の研究はNEDOおよび産総研-東工大RWBC-OILの支援を受け行われました。
]]>エクサスケール時代に向け超ビッグデータ応用の実現支援が重要となるなか、DRAMと不揮発メモリ(NVM, ここでは主にFlash)等からなるメモリ階層を持つ計算機、それらを多数持つ大規模システムにおけるプログラミングシステムの研究を行いました。ComEX-PMとvGASNetの提案・研究・開発により、片方向通信とNVMの利用を効率的に可能とします。特にvGASNetでは協調キャッシュの導入により、片方向通信の欠点の一つであるスケーラビリティの問題を大幅に改善しました。
 2019年1月10日に公聴会が行われ、その後の審査等を経て学位授与が決定しました。
2019年1月10日に公聴会が行われ、その後の審査等を経て学位授与が決定しました。
在学中の研究内容の一部にはJST-CRESTおよび産総研・東工大RWBC-OILの文脈によるものが含まれます。
]]>ニューラルネットワーク(NN)のモデルが複雑になる場合に、GPUメモリ容量が不足して学習ができなることがあります。そのような場合の解決のために、NNの構造全体を考慮する最適化技術PoocH(Profiline based out-of-core Hybrid method)およびChainerフレームワークの改造による実装・評価を行いました。

研究内容にはIBM東京基礎研との共同研究の内容を含みます。
研究成果を https://github.com/yukiito2 にて公開中です。
]]>場所:西7号館302号室 (建物入口のすぐ左手)
出席希望者は、前もって endo[at]is.titech.ac.jp にメールもしくは、Twitter ToshioEndoに連絡もらえると助かりますが、予告なしでも大丈夫です。
時間の都合がつかないが話を聞いてみたい、という場合も上記に連絡ください。
]]>詳細は下記へ⇒ 2018年度 数理・計算科学系入試説明会
]]>場所:西7号館203号室集合 → 会場へ (直接下記会場に来てokです)
出席希望者は、前もって endo[at]is.titech.ac.jp にメールもしくは、Twitter ToshioEndoに連絡もらえると助かりますが、予告なしでの参加もお気軽にどうぞ。
どちらにも都合がつかないが話を聞いてみたい、という場合も上記に連絡ください。
]]>



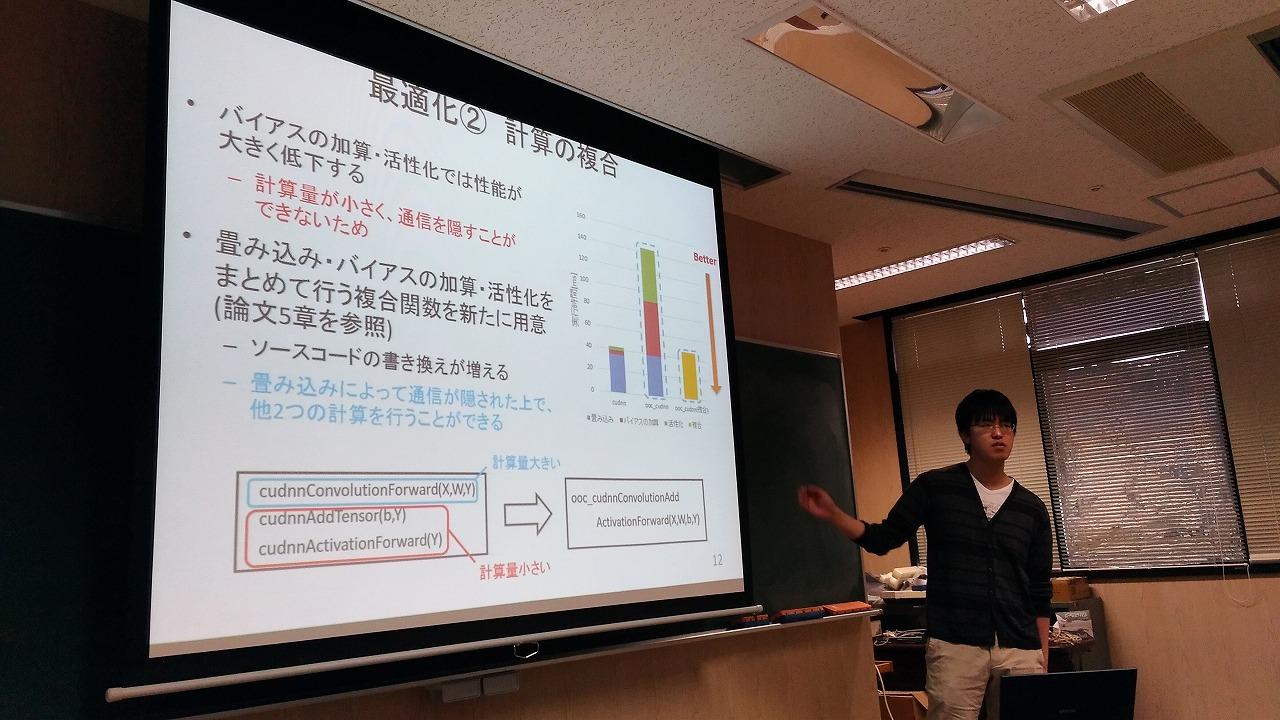
Convolution Neural Networkの演算はGPGPUにより高速に行うことができる一方、計算のサイズについてはGPUのメモリ容量(数~十数GBで、ホストメモリより小さい)により限定されます。その容量を超えるようなサイズの計算が可能で、cuDNNライブラリと互換性を持つooc_cuDNNライブラリを開発中で、性能モデルによる最適化も行っています。
4月に虎ノ門で行われるxSIG会議での発表も決まっています。
Ryo Matsumiya, Toshio Endo: PGAS Communication Runtime for Extreme Large Data Computation
PGAS(partitioned global address space)システムであるGlobal Arraysを用いたアプリケーションに対して,実メモリ容量を超えるような実行(out-of-core実行)を透過的に実現するライブラリの設計・評価について発表しました.





※発表会での写真がピンボケしてしまったため、後日の説明の様子
]]>