Research
遠藤研究室では、スーパーコンピュータや高性能計算システムのためのソフトウェアの研究を行っています。
スパコン・高性能計算システムとは?
現在の科学の進展は計算機によって支えられており、「実験・観測」、「理論」に続く第三の科学として確立されています。
- 実験・観測による科学:高性能な望遠鏡・粒子加速器(Spring-8のような)が必要
- 理論による科学:高度な数学の裏付け・発展が必要
- 計算による科学:高性能な計算機・スパコン(東工大TSUBAME・理研 富岳・産総研ABCIのような)と、それを支えるソフトウェアが必要
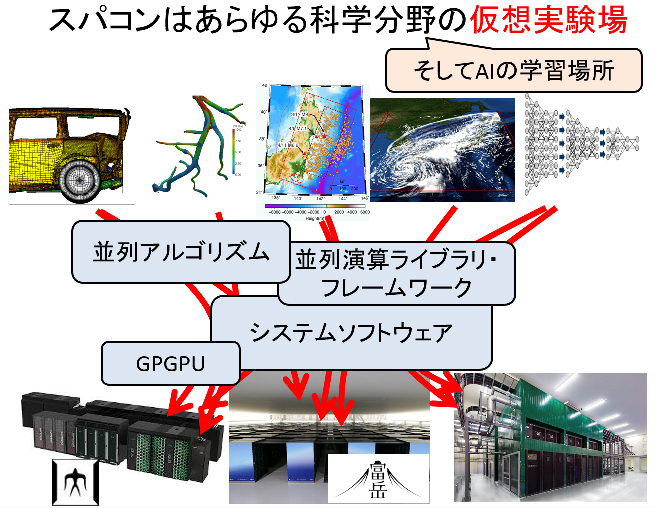
さらに社会学・経済学・ものづくり...でもスパコン利用は広がっており、特に近年ではディープラーニングをはじめとする機械学習・AI技術において、スパコンや高性能なソフトウェア技術の進展は必須となっています。
システムソフトウェアの進展の必要性
利用が広がる一方で、スパコンを有効利用するためには、(1) 並列計算が必須、(2) スパコンのアーキテクチャはさらに年々複雑になっている、という困難さがあります。
様々な(理論・モデルが複雑化する)応用分野と、様々な(構成が複雑化・大規模化する)スパコンアーキテクチャの、橋渡しをするシステムソフトウェアの進展が求められています。
より具体的には、現在デファクトスタンダードとなっている並列プログラミング環境であるMPI・OpenMPや、GPU並列計算環境のCUDAやOpenACCをベースとして、主に以下のような問題意識で研究します。
- プロセッサ数・並列度が数百万・数億以上となったときに対応できるか?
- メモリ階層・プロセッサ構成が今より複雑に・階層的になったときにプログラミングしやすくするには?
- ソフトウェア実行中の電力を削減するには?
学位論文
2023年度修士論文
- 瓜生 侑:ステンシル計算の時間ブロッキングフレームワークの実装と評価
- 大沢 泰生:タンパク質構造予測プログラムOmegaFold のマルチGPU を用いた高速化
2023年度(秋季)博士論文
- Wang Chenyu: GPU-Based Acceleration and Optimization Research on Computer Vision
- Zhang Lingqi: Overcoming the Gap Between Compute and Memory Bandwidth in Modern GPUs
2022年度修士論文
- Ivanov Ivan Radanov: Optimizations and Transformations of Parallel Code via High Level Intermediate Representation
- 細木 隆豊:深層学習におけるハイブリッドパイプライン並列による高速化手法の提案と学習精度の評価
- 丸山 翼:機械学習を用いた音声言語処理に向けたデータ拡張手法の研究
2022年度卒業論文
- 伊藤 丞:コンシューマー向けGPUにおけるメモリ節約版stable diffusion の改善
- 岡本 洸琉:動的スケジューリングライブラリを用いたPython における分散コレスキー分解の実装と評価
- 神戸 風太:GPU上のTensor core を使ったステンシル計算の時間ブロッキングによる高速化
2022年度(秋季)修士論文
- 相川洋貴:境界条件を含むステンシル計算のドメイン特化言語による記述とCPU・GPU 上の性能評価
2021年度卒業論文
- 瓜生侑:C++17における実行ポリシーを用いた並列プログラムの実装とCPU・GPU上の評価
- 大沢泰生: 大規模データセットのために異種ストレージ領域を活用したAlphaFold2 の最適化
2020年度卒業論文
- 細木隆豊:GPUクラスタにおけるハイブリッド並列DNN学習のボトルネック分析
- Ivan Radanov Ivanov: Improved failover for HPC interconnects through localised routing restoration
2020年度(秋季)卒業論文
- 相川洋貴:時間ブロッキングを用いたステンシル計算のドメイン特化言語による高性能実装と評価
2018年度博士論文
- 松宮遼:Integration of Non-volatile Memory into One-sided Communication for Extreme Big Data Applications (エクストリームビッグデータアプリケーションのための不揮発性メモリの片方向通信への融合)
2018年度修士論文
- 伊藤祐貴:GPUメモリ管理の実行時最適化による大規模深層学習の高速化
2017年度修士論文
- 見村朔:映像分類システムにおける機械学習の高速化にむけて
2016年度卒業論文
- 伊藤祐貴:メモリ階層を利用した大規模深層学習手法と性能モデリング
2015年度修士論文
- 佐々木 尚人:時間発展アプリケーションにおけるチェックポイントデータの非可逆圧縮手法の提案と評価
- 辻田 裕紀:マルチGPU・マルチノード環境のメモリ階層に適応した数理最適化ソルバー向けスケジューリング手法
- 都筑 一希:CPU・GPU混載ノードにおける性能・消費電力モデルを用いたオンライン電力制御手法
2013年度卒業論文
- 佐々木 尚人:科学技術計算におけるウェーブレット変換を用いたチェックポイントデータの圧縮
- 辻田 裕紀:GPU上の数理最適化ソフトウェアに対する データドリブン型アルゴリズムによる 通信量削減
- 都筑 一希:CPU・GPU混載ノードにおける電力・性能モデルの構築
これまでの・進行中の研究課題
- スパコンの混雑による待ち時間を大幅に減らす・ゼロにすることによるインタラクティブ・リアルタイムHPCの実現(富士通と共同)
- マルチGPU上で稼働する並列アプリケーションを、容量の限られたGPUメモリサイズを超えた実行を可能とするシステムソフトウェアHHRTを開発。メインメモリやFlash SSDのメモリ階層の容量を利用可能に
- 「二位じゃダメなんですか」で知られるLinpackベンチマークで1.19PFlopsの性能を達成。最高順位世界4位 (2010年)。(松岡聡研究室や各ベンダーと共同)
- 油浸冷却方式を用いるTSUBAME-KFCスパコンで省エネ世界一(2013年)。(松岡聡研究室や各ベンダーと共同)
- 金属結晶の成長シミュレーションで2.0PFlopsの性能を実現。本分野の著名な賞であるGordon Bell賞受賞。(GSIC 青木尊之研究室などと共同)
- 数理最適化問題の一種である半正定値計画問題を解くソフトウェアSDPARAにて、1.7PFlopsの性能と、問題規模の世界記録を実現。(藤澤克樹研究室などと共同)